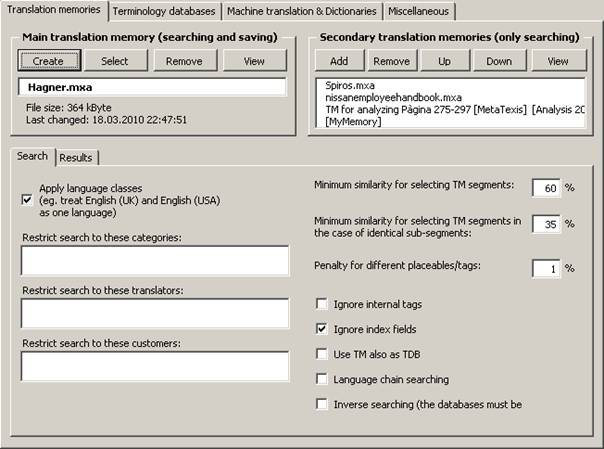
Translation memories are configured via the Translation memories tab:
In the following sections, the options are explained in detail.
Defining the Main TM (Scout)
To select an existing TM:
1. Click the Select button in the Main translation memory frame.
2. In the dialog box shown, select a database type (see Database Servers).
3. If you have selected the local database type, another dialog box will be shown. Select a TM, as appropriate.
To create a new TM:
1. Click the Create button in the Main translation memory frame.
2. In the dialog box shown, select a database type (see Local MetaTexis Databases).
3. In the following dialog box, select a directory and define a name for the new TM.
To remove a main TM:
1. Click the Remove button in the Main translation memory frame.
To view the main TM:
1. Click the View button in the Main translation memory.
Defining Secondary TMs (Scout)
To add a TM to the list of secondary TMs:
1. Click the Add button in the Secondary translation memories frame.
2. In the dialog box shown, select a database type (see Database Servers).
3. If you have selected the local database type, another dialog box will be shown. Select a TM or TDB, as appropriate.
To remove a TM from the list of secondary TMs:
1. Click the Remove button in the Secondary translation memories frame.
To move a TM up or down in the list of secondary TMs:
1. Click the Up/Down button in the Secondary translation memories frame.
To view the secondary TM:
1. Click the View button in the Secondary translation memories frame.
TM search options (Scout)
There is one tab containing the TM search parameters. It has the following appearance:
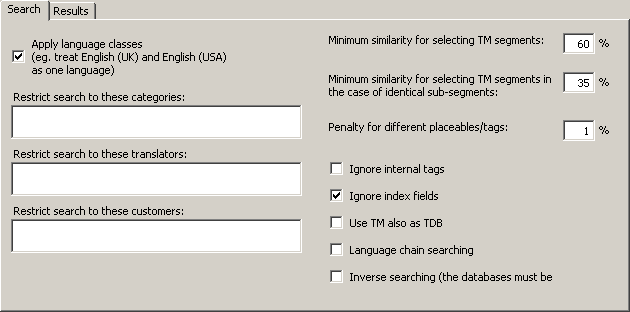
The Search tab contains the following elements:
· Apply language classes:
If this checkbox is checked, MetaTexis will look for language classes rather than for the exact language defined. There are several languages that have variants. For example, there are many variants of the English, French and Spanish languages. If language classes are applied, MetaTexis treats the variants of a language as the same language, e.g. English (UK) and English (USA) are treated as one language. So, if a TM contains segments in different languages that belong to the same language class (e.g. "English (UK)" and "English (US)"), they are all included in the search. On the other hand, if this checkbox is unchecked, MetaTexis will only include the segments that are in the same language as the source language of the MetaTexis document (see Document options).
· Restrict search to these categories:
If you enter a category in this text box, the TM search is restricted to segments with this category. You have to be careful with this command: Make sure that the category entered actually exists in the TMs.
If you enter more than one category, they must be separated by a semicolon.
· Restrict search to these translators:
If you enter a translator name in this text box, the TM search is restricted to segments whose last editor is one of the specified translators. You have to be careful with this command: Make sure that the translators entered actually exist in the TMs.
If you enter more than one translator, they must be separated by a semicolon.
· Minimum similarity for selecting TM segments:
In this text box, you define the lower limit of similarity which a TM segment must reach to be presented to the translator. The percentage refers to the number of words which are identical. A TM segment in a database is only selected if at least X % of the words are identical with the words of the source segment searched for.
Example: You have defined 60% as the minimum level of similarity (default). And you want to translate the sentence: "He loves Alicia." You let MetaTexis search for TM segments in the main TM, which contains only three segments (and their translations): 1) "He hates Enrique.", 2) "He wants Alicia.", and 3) "He loves Shakira.". TM segments 2) and 3) are selected because 2 of 3 words are equal (66.6%), whereas TM segment 1) is not selected because only one word is equal (33.3%).
· Minimum similarity for selecting TM segments in case of identical sub-segments:
In some cases, it can make sense to select a segment from a TM even if the minimum similarity has not been reached, namely when a sub-segment is identical.
Example: In the two sentences, "She loves Enrique desperately, but hopelessly." and "She loves Enrique.", the sub-segment "She loves Enrique" is identical. The similarity value is 50%. Therefore, "She loves Enrique" does not meet the normal minimum similarity criterion, based on the number of words. However, if the similarity criterion for sub-segments is less than 50%, the segment is selected from the TM, after all.
Note: The settings made in this tab have great impact on the speed of the search process when the TMs are big: The lower the values, the slower the search process. The higher the values, the faster the search process.
· Ignore index fields:
This checkbox is not shown for tagged documents. If this checkbox is active, index fields in TUs are ignored when MetaTexis executes TM searches, and TUs are saved without any index fields, if RTF saving is active.
· Ignore internal tags:
This checkbox is only shown for tagged documents. If this option is checked, internal tags will be ignored and not be saved in the TM. This is relevant for tagged documents such as HTML or XML documents. You are advised to activate this option because internal tags usually only contain formatting information.
· Use TM also as TDB:
If this option is checked, the TM will not only be searched as TM, but also as TDB, that is, the TUs in the TM will be treated as terminology. This can further increase your translation efficiency, for example, when the text to be translated contains segments consisting of several smaller sentences has already been previously translated.
· Language chain searching:
If this option is checked, the search will be extended to find more TUs if the TM contains multi-lingual content. For example, lets assume that you are translating a text from English to French (EN->FR). If the TM contains TUs in the language combinations EN->IT and IT->FR, where one EN segment is very similar or identical to the segment currently searched, the TM search will usually not be successful because there is no EN->FR dataset in the TM. However, if the language chain searching is active, MetaTexis will look further, and, if the IT segments are identical, MetaTexis will actually find the French translation of the Italian text and assign it to the English source text, and a EN->FR hit will be displayed. This search even works across TMs!
Moreover, if inverse searching is active, the language chain search even works if the language directions are mixed, e.g. MetaTexis will find a match if the TM has the TUs IT->EN and FR->IT.
· Inverse search (the databases must be enabled for inverse searching):
If this option is checked, the TMs will also be searched for matches with the opposite language direction. This option only works if the database is activated for inverse searching and saving when it is created (see Local MetaTexis Databases). Combined with the language chain searching feature, this opens up amazing possibilities (see above).
TM search results options (Scout)
The Results tab contains the parameters for how the search results (if any) are shown:
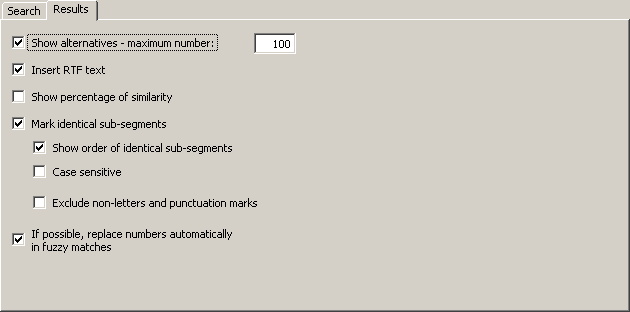
The following settings can be performed:
· Show alternatives - max number:
If this checkbox is checked, not only the best match is presented, but also the alternatives, up to a maximum number to be specified in the text box.
If this checkbox is not checked, only the best match is presented.
· Insert RTF text:
If this checkbox is checked, the RTF text stored in the TM is inserted. In this case, all formatting information saved in the RTF text is preserved.
If this checkbox is not checked, the "pure" text stored in the TM is inserted. In this case, no formatting information is included.
Usually you will choose to insert the RTF text. However, in some cases, you might prefer to insert the "pure" text.
Note: Any TU is stored both as RTF text including formatting information and as Unicode text without formatting information. Saving the raw text in the Unicode format (rather than in the ASCII format) means that characters of all kinds (be they Russian, Latin, or Sanskrit, as well as all special characters in the different languages) are displayed correctly on any computer.
· Show percentage of similarity:
If this checkbox is checked, the percentage of similarity is displayed at the beginning of the TM segments, e.g. "{78%}". In most cases, this information is not needed, because you can also get this information by displaying the Segment info dialog box (see Segment Info), and because the segment comparison function tells you much more than the percentage of similarity (see next paragraph).
· Mark identical sub-segments:
If this checkbox is checked, identical sub-segments will be marked according to your settings in the General options dialog box (see Settings for Segment Comparison). By default, identical sub-segments are marked by means of green characters, whereas different sub-segments are marked via a so-called "marching ants" box around them. This means, you can actually see which sub-segments are identical, so that you are able to compare the source segment with the TM segment very quickly, thus enabling you to quickly adapt the translation of the TM segment (for more information and an example, see Searching in TMs).
▪ Show order of identical sub-segments:
If this checkbox is checked, the order of the identical sub-segments is indicated by numbers placed directly in front of the identical sub-segment. This makes comparing source segment and TM segment even easier.
▪ Case sensitive:
If this checkbox is checked, the segment comparison is executed as case sensitive. Usually it makes more sense to leave this check box unchecked.
▪ Exclude non-letters and punctuation marks:
If this checkbox is checked, the segment comparison excludes non-letters and punctuation marks. Usually you have a better overview when this checkbox is not checked.
· If possible, replace numbers automatically when the match is not perfect:
If this checkbox is checked, and if the matches found are not perfect, any numbers found will be replaced automatically according to a replacement algorithm which puts main emphasis on secure replacements. As a result, the number of 100% matches can be increased, reducing the amount of work needed even further.