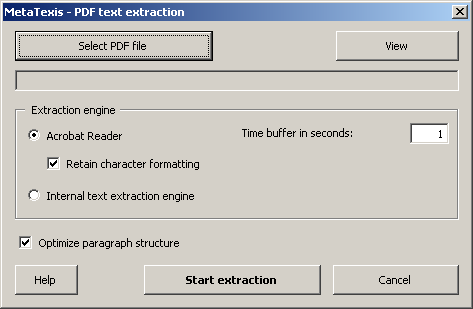
To import texts from PDF files click the command Extract text from PDF files in the Import/Export sub-menu. The following dialog will be displayed:
To extract text from a PDF file, execute the following steps:
1. Click the Select PDF file button and select a PDF file. Its name will be display in the grey text box below. (To view the PDF file in a PDF reader, click the View button.
2. In the frame Extraction
engine, select the method to be used for the text extraction. You can choose
between two option: Acrobat Reader
and Internal text extraction
engine.
When the Acrobat Reader is used, the text is retrieved by calling
up the Acrobat Reader program that must be installed on the local
system.
When the internal text extraction engine is used, MetaTexis extracts
the text without the Acrobat Reader.
In many cases the Acrobat Reader gives
better results, whereas the internal engine is much faster.
3. If the PDF document to be imported is very big or if your computer is rather slow, you might have to define a higher Time Buffer in seconds than the default value 1. You might have to experiment until you have found the right setting. For small PDF documents, the default value 1 should work well.
4. If you would like to retain the character formatting given in the PDF document, activate the checkbox Retain character formatting.
5. As the PDF format is layout-oriented and not text-flow oriented like text editors, the text is retrieved line-wise from a PDF document. To reduce the manual effort in preparing the extracted PDF text for preparation, activate the option Optimize paragraph structure. If this is active, MetaTexis will apply some algorithms to reduce the number of paragraph breaks as much as possible.
6. To start the extraction process, click the Start extraction button.
7. After the extraction has finished check the imported text regarding line and paragraph breaks. You might have to delete paragraphs or to add them in certain cases, depending on the type PDF document imported.
Note: The PDF file format is layout-oriented. To extract text from a PDF file correctly can therefore be a very tricky task. The MetaTexis text extraction offers some basic functions, but it cannot retain the layout of the PDF document. If this is important for your special translation need, please use one of the special PDF extraction programs (like Solid Converter PDF, or ABBYY PDF Transformer, or others).