The most important settings are made in the two frames: Segmentations marks and Follow-up marks. Here, you define which characters are treated as separation marks by the segmentation engine.
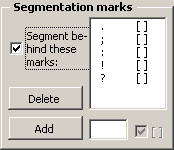
For most languages, these five characters are defined as the default segmentation marks: " . : ; ! ? ". The "[ ]" sign behind each character indicates that the segmentation mark must be followed by a space. Here is an example for a Latin language like English, German, French, or Spanish:
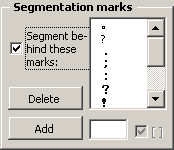
For Chinese, Japanese and Korean languages, by default other characters are defined as segmentation marks, as appropriate for the individual language. In these languages, the segmentation marks are not followed by a space; therefore, there is no "[ ]" behind each character in the segmentation marks list. Here is an example for the Japanese language:
If the segmentation engine finds one of these characters in a paragraph, and if it is followed by a space or by a Follow-up mark and a space, the paragraph will be segmented behind the space.
If you deactivate the Segmentize at these marks checkbox, or if you delete all characters from the list of segmentation marks, no paragraph will be segmented, i.e. each paragraph will be treated as one segment.
To add a segmentation mark into the segmentation marks list:
1. Enter a character or a string in the text box located next to the Add button.
There are two special strings with special meanings:
▪ "{TAB} is interpreted as the tabulator sign
▪ "{BR} is interpreted as a line break
▪ "{SP} is interpreted as a space
▪ Any Unicode character can be entered by putting the decimal Unicode value in brackets, e.g. "{160}.
2. If a space character behind the string is required check the [ ] check box behind.
When you enter a character from a Latin character set, the checkbox is checked by default; otherwise, it is not checked.
3. Click the Add button.
Note: You can use separation marks for different character sets at the same time. For example, you can use English separation marks and Japanese separation marks at the same time. This is very useful, if you need to translate a text that includes both English and Japanese sentences.
In many cases, it does not make sense to segment at a special location, even if there is a segmentation mark and a space. Theses cases can be defined in the Abbreviations and Miscellaneous frames.